研究ハイライト
合成画像のAI学習で種子の形態評価を効率化 〜植物科学・農学分野における機械学習モデルの開発の高速化に期待〜
名古屋大学トランスフォーマティブ生命分子研究所(WPI-ITbM※)の戸田陽介特任助教と、大阪大学産業科学研究所の大倉史生助教らの研究チームは、画像解析および人工知能(AI)技術を応用し、1枚の画像から一度に数百粒の種子の形を自動かつ高精度に測定するシステムを開発しました。種子の形は、作物の収量や品質と密接に関連のある重要な農業形質であり、画像から種子の形状を自動測定して評価することは、効果的な作物品種の創出に欠かせない技術です。しかし、種子のように数の多い物体の教師データ注1)作成は手間がかかり、多様な作物種を高速かつ簡便に測定することは困難でした。
今回、戸田特任助教らの研究チームは、大麦種子画像を仮想空間上にランダムに合成することで、教師データに使われる画像を大量に自動生成し、機械学習(深層学習)モデルの効率的な訓練を行う手法を構築しました。実際に合成データのみを用いて学習を行ったところ、手作業で測定するときと同程度の精度で、画像からの種子の検出と形状の抽出が可能であることを示しました。さらに、同様の手法は、イネ、コムギ、エンバク、レタスなど数多くの品種の種子の測定に対しても応用可能であることを示しました。
品種間での見た目の違いが大きい植物の画像解析において、機械学習モデルの訓練に重要となる教師データの構築は悩みの種です。本アプローチを応用することで、作物の種子測定のみならず、作物の多様な表現型を計測するための機械学習モデル開発の高速化につながるものとして期待されます。
本研究成果は、国際科学誌Nature Communications Biology において2020年4月15日18時(日本時間)に公開されました。
【研究の背景と内容】
これまで人類が経験したことのない気候変動と人口増加が続く中、持続的な食糧生産を続けるためには、より良い作物品種を創出・選抜する育種(品種改良)をいち早く行う技術の構築が喫緊の課題です。品種の選抜を行うためには、「良い品種」であることを効率的に評価する必要があります。種子の形(長さ、太さなど)は、作物の収量や品質と密接に関連のある重要な形質であることが知られており、育種における重要な評価尺度であると考えられています。しかし、小さな種子一粒一粒の形状を手で計測することは非常に困難な作業であり、人工知能(AI)技術を活用した自動化が期待されています。
近年、植物の表現型を計測する植物フェノタイピング注2)分野において、深層学習を用いた画像解析が盛んに用いられています。本研究では、深層学習によるインスタンスセグメンテーション注3)を用い、1枚の画像から、数百粒の種子の形状を自動取得するシステムの開発を目的としています(図1)。

(上部:入力画像、下部:本研究における検出結果)
深層学習を活用するためには、教師データが必要です。一般に、インスタンスセグメンテーションの教師データは、色塗りによるラベル付けなどを中心とした手作業で行われています。しかし、図1における種子のように、数の多い物体の教師データの作成は非常に手間がかかる(例えば、品種ごとに数十~数百の画像を用意し、それぞれに対して数百の種子を一粒ずつ色塗りするような作業が求められる)ため、多様な品種・作物種を高速かつ簡便に測定することはこれまで困難でした(図2上段)。
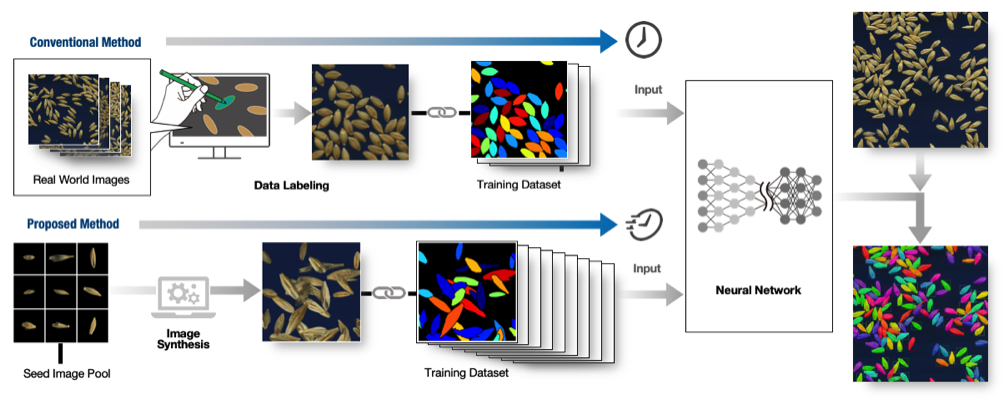
そこで、戸田特任助教らの研究グループは、少数の種子のサンプルのみから大量の教師データを自動生成し、機械学習(深層学習)モデルの効率的な訓練を行う手法を構築しました。本手法は、ドメインランダム化注4)と呼ばれるアプローチの一種であり、教師データの作成の手間を省き、機械学習モデル開発の高速化に役立てるものです。提案手法では、形状の情報があらかじめ付与された少数の大麦種子のサンプル画像を仮想空間上にランダムに配置し、合成画像を多数作成します(図2下段)。実際に合成データのみを用いて学習を行ったところ、手作業で測定するときと同程度の精度で、画像からの種子の検出と形状の抽出が可能であることを示しました。
本システムは様々な種子の配置に対応しており、図1のような、無造作にばら撒いた種子を撮影するだけで、一粒一粒の種子の形状を自動で取得します。インスタンスセグメンテーションによる形状情報からは、長さ、太さなどにとどまらない、面積や輪郭形状などの詳細な特徴を見出すことができます。本研究で構築したシステムにより、実際に品種ごとに異なる形状の特徴が得られることが明らかになっています。今後、品種や生育環境による詳細な違いを定量化し、育種の強力なツールとして活用することが期待されます。
さらに、同様の手法は、イネ、コムギ、エンバク、レタスなど数多くの品種の種子の測定に容易に応用が可能であることも、本研究で明らかになりました。この結果は、作物種を問わず、多様な種子の自動測定が実現可能であることを強く示唆しています。
【本研究の意義と今後の展開】
本研究成果は、簡便かつ効率的な種子の形状解析を実現します。大規模な気候変動が続く中での持続的な食糧生産のためには、育種(品種改良)のサイクルをスピードアップし、優良な品種を迅速に創出していくことが不可欠です。種子の形状を用いた品種の評価は、育種における強力な基盤ツールとなります。また、品種評価のみならず、これまで人間の目では気づけなかった詳細な種子の特徴を見出すような、植物科学分野における意義も期待できます。
インスタンスセグメンテーションをはじめとする画像解析の研究の多くは、車や人などを含む既存のデータセットを対象として行われています。一方、植物の画像解析では、品種や部位、個体間での見た目の違いが大きい特性があるため、応用場面によって毎回異なる教師データを作成する必要があります。他の多くの応用においてもそうですが、特に植物において教師データの作成は大きな悩みの種です。本研究で採用した、人工的な教師データ生成による手法は、様々な場面で活用することができます。今後、本研究における取り組みをきっかけとして、本研究の成果は作物種子の測定のみならず、植物表現型の計測のための機械学習モデル開発の高速化につながるものとして期待されます。
【用語説明】
注1)教師データ (training data)
機械学習の中でも特に教師あり学習と呼ばれる際に使用される、人間が用意した例題と答えがセットになったデータ。本研究では、種子の写真と、種子ごとに色分けしたマスク画像を指す。
注2)植物フェノタイピング(plant phenotyping)
植物の育種では、様々な品種を作成・選抜します。この際、「良い品種」であることをいかに高速に、かつ効率的に評価するかが重要になります。植物フェノタイピングは、植物の見た目(表現型)を定量的・定性的な値として求める技術であり、品種の良し悪しを評価することが可能となります。種子だけでなく、植物の地上部(茎や葉、果実など)や根、機能(光合成活性、乾燥耐性)など、計測対象は多岐にわたります。近年は、大量の個体の詳細な情報を効率的に取得できる、画像解析による植物フェノタイピングが盛んに研究されています。
注3)インスタンスセグメンテーション(instance segmentation)
画像に写った一つ一つの物体を見つけ、かつその領域を分割する手法を指します。近年、深層学習を用いたインスタンスセグメンテーションが様々な分野で盛んに改良・活用されています。例えば、車載画像から車や人を見つける技術は自動運転への応用が期待されており、植物フェノタイピングの分野でも、葉の検出・領域分割などに活用されています。教師データとして必要となる、各物体を領域分割した(少なくとも数十枚以上の)画像を作成することに非常に手間がかかることが、実用上の問題として挙げられます。
注4)ドメインランダム化(domain randomization)
深層学習などの学習用データをコンピュータシミュレーションなどにより人工的に生成する際、生成画像と実環境の違い(ギャップ)がしばしば問題になります。ドメインランダム化は、画像を生成する際、様々な環境の違いをランダムに再現することにより、実環境でのデータ作成をすることなく、このギャップを埋めようとする手法です。従来、光源の違いや物体の位置など、様々なランダム化が試みられてきました。本研究では、少数の種子画像をランダムに配置することで、実環境における様々な種子の配置をカバーしました。
【論文情報】
掲載雑誌:Nature Communications Biology
論文名:Training instance segmentation neural network with synthetic datasets for crop seed phenotyping
著者:Yosuke Toda, Fumio Okura, Jun Ito, Satoshi Okada, Toshinori Kinoshita, Hiroyuki Tsuji, Daisuke Saisho (戸田陽介、大倉史生、井藤純、岡田聡史、木下俊則、辻寛之、最相大輔)
論文公開: 2020年4月15日18時(日本時間)
DOI: 10.1038/s42003-020-0905-5I
本成果は、JSTさきがけ(JPMJPR17O5, JPMJPR17O3)、JST CREST (PMJCR16O4)、日本学術振興会科学研究費(16H06466, 16H06464, 16KT0148, 19K05975)、JST ALCA (JPMJAL1011) の支援のもとで得られたものです。
2020-04-16